Infrastruktura opracowana w Instytucie Języka Polskiego PAN w latach 2021–2023 w ramach projektu DARIAH.LAB, łącząca zasoby języka mówionego z narzędziami umożliwiającymi ich przetwarzanie, przeszukiwanie i analizę.
Celem projektu było stworzenie infrastruktury umożliwiającej pozyskiwanie, przetwarzanie i udostępnianie zasobów języka mówionego, odpowiadającej na aktualne potrzeby badań nad współczesną polszczyzną. Jednym z kluczowych założeń było uzupełnienie luki w dokumentacji języka mówionego po roku 2010, pozostawionej przez dotychczasowe zasoby referencyjne, poprzez opracowanie korpusu nagrań obejmującego lata 2011–2020, stanowiącego zarówno uzupełnienie istniejących zasobów, jak i podstawę do ich dalszego rozwijania. Istotnym celem było również uchwycenie zmian w komunikacji językowej wynikających z rozwoju środowiska cyfrowego, w którym znacząca część współczesnej polszczyzny mówionej funkcjonuje w przestrzeni online, co pozwala na analizę autentycznych form użycia języka. Projekt zakładał ponadto stworzenie rozwiązań umożliwiających systematyczne gromadzenie i aktualizację danych, dzięki czemu zasób ma charakter otwarty i może być rozbudowywany o kolejne nagrania, odzwierciedlając bieżące zmiany zachodzące w języku.
Infrastruktura
SpoCo – infrastruktura do tworzenia korpusu
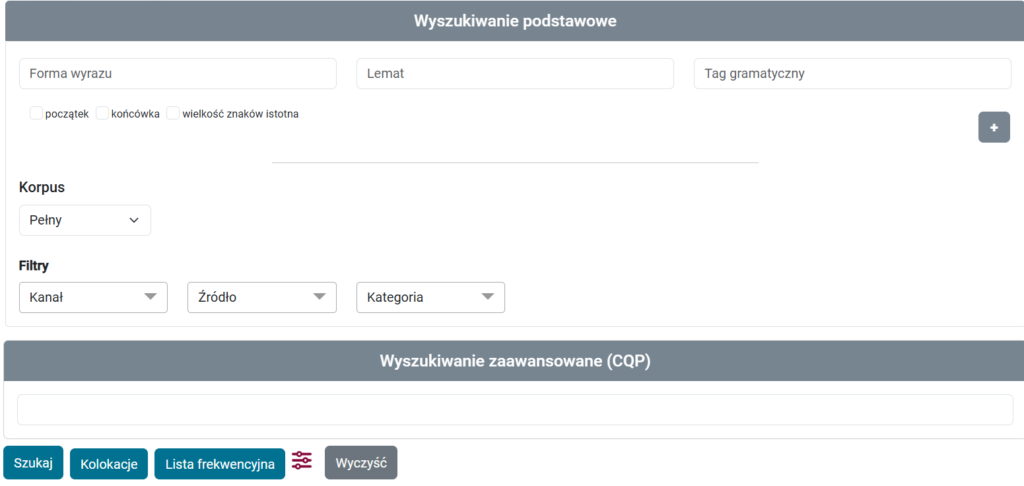
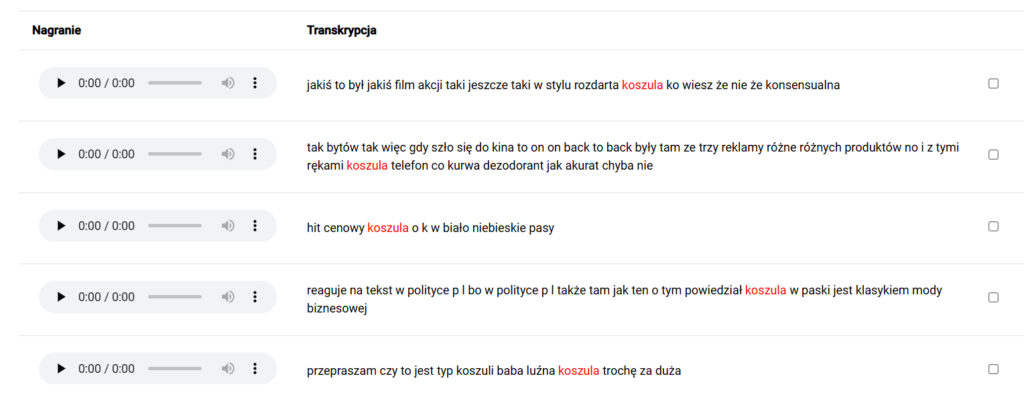
SpoCo to przeglądarkowy interfejs korpusowy rozwijany w Instytucie Języka Polskiego PAN, pełniący funkcję głównego narzędzia dostępu do zasobów mówionych udostępnianych w ramach Korpusu Mowy. W projekcie DARIAH.LAB został on rozbudowany i dostosowany do pracy z danymi języka mówionego. System umożliwia wyszukiwanie form wyrazowych, lematów oraz informacji gramatycznych, formułowanie zapytań w języku CQL, generowanie konkordancji, analizę współwystępowania jednostek oraz tworzenie zestawień frekwencyjnych. Wyniki prezentowane są jako fragmenty nagrań audio powiązane z odpowiadającymi im odcinkami transkrypcji, co pozwala na analizę kontekstu oraz odsłuchanie rzeczywistej realizacji fonicznej. Dzięki swojej elastyczności i skalowalności SpoCo stanowi trwałe środowisko badawcze, wykorzystywane nie tylko w Korpusie Mowy, lecz także w innych projektach badawczych.
ZASOBY
Korpus Mowy 2011-2020 i lat późniejszych
W ramach projektu zgromadzono ponad 1 000 godzin nagrań języka mówionego, obejmujących audycje, wywiady i podcasty pochodzące z różnorodnych źródeł internetowych. Dobór materiału był kontrolowany pod względem czasu powstania, tematyki oraz charakteru wypowiedzi, co pozwoliło na stworzenie zróżnicowanego zasobu współczesnej polszczyzny mówionej.
Źródła danych
Zgromadzone nagrania zostały przekształcone do postaci tekstowej z wykorzystaniem technologii automatycznego rozpoznawania mowy, a wybrana część zasobu poddana została ręcznej korekcie, co umożliwia prowadzenie analiz wymagających wysokiej jakości danych. Materiał uzupełniono o zestandaryzowane metadane opisujące każde nagranie oraz warstwy anotacyjne wspierające jego przetwarzanie i przeszukiwanie. Istotnym elementem opracowania jest również segmentacja nagrań na spójne jednostki wypowiedzi, umożliwiająca ich powiązanie z transkrypcją oraz analizę struktury dialogów. Dodatkowo dane zostały opatrzone informacją gramatyczną zgodną z praktyką Narodowego Korpusu Języka Polskiego, co pozwala na formułowanie zaawansowanych zapytań i prowadzenie pogłębionych analiz językowych. Połączenie warstwy dźwiękowej, tekstowej, anotacyjnej i metadanych tworzy spójny zasób badawczy, stanowiący podstawę analiz współczesnej polszczyzny mówionej.